Empirical Study on Model Compression Techniques for Efficient Deployment of Large Language Models and Scalable Diffusion Models with Transformers
Supervisor: Prof. Luo Ping, Second examer: Prof. Kong Lingpeng
Student: Li Zhiqian
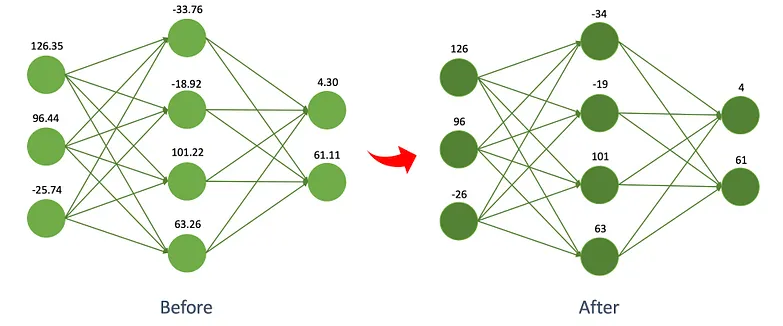
Large Models can be compressed into smaller-size models with Quantization!
Quantization is a model size reduction technique that converts model weights from high-precision floating-point representation to low-precision floating-point (FP) or integer (INT) representations, such as 8-bit or 4-bit.
Key Techniques in Model Compression
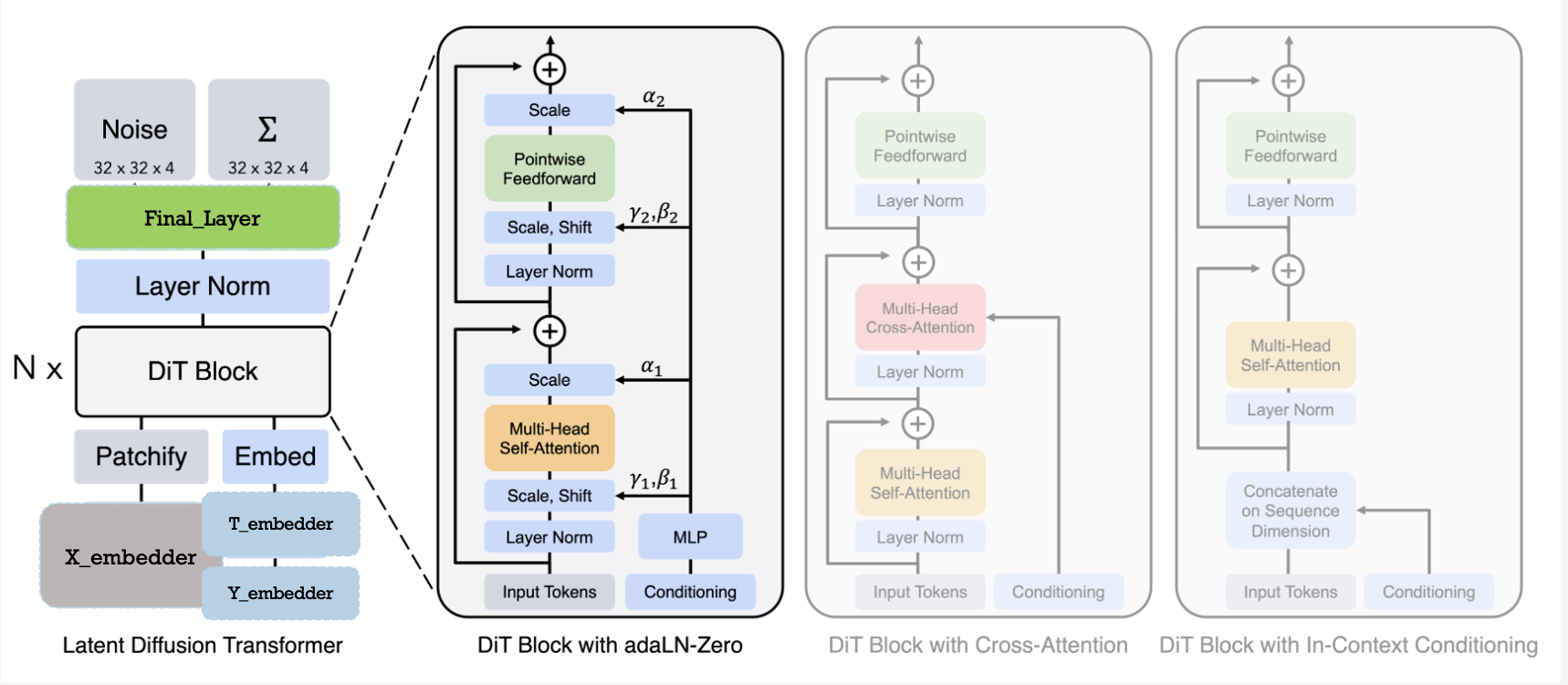
Apply them to Large Language Models(LLMs) and Scalable Diffusion Models with Transformers(DiTs)
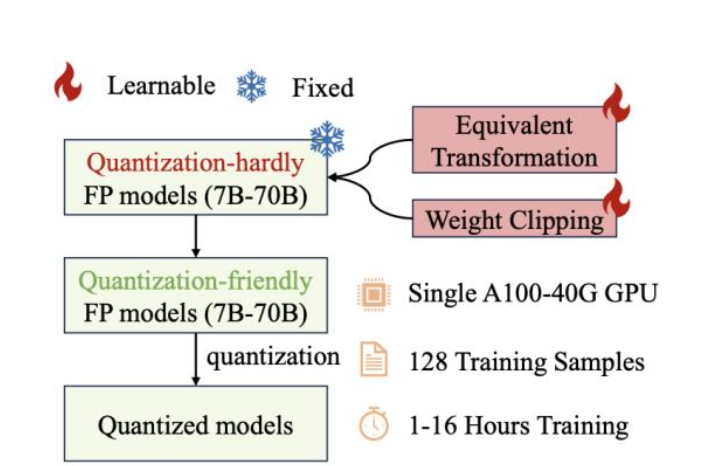
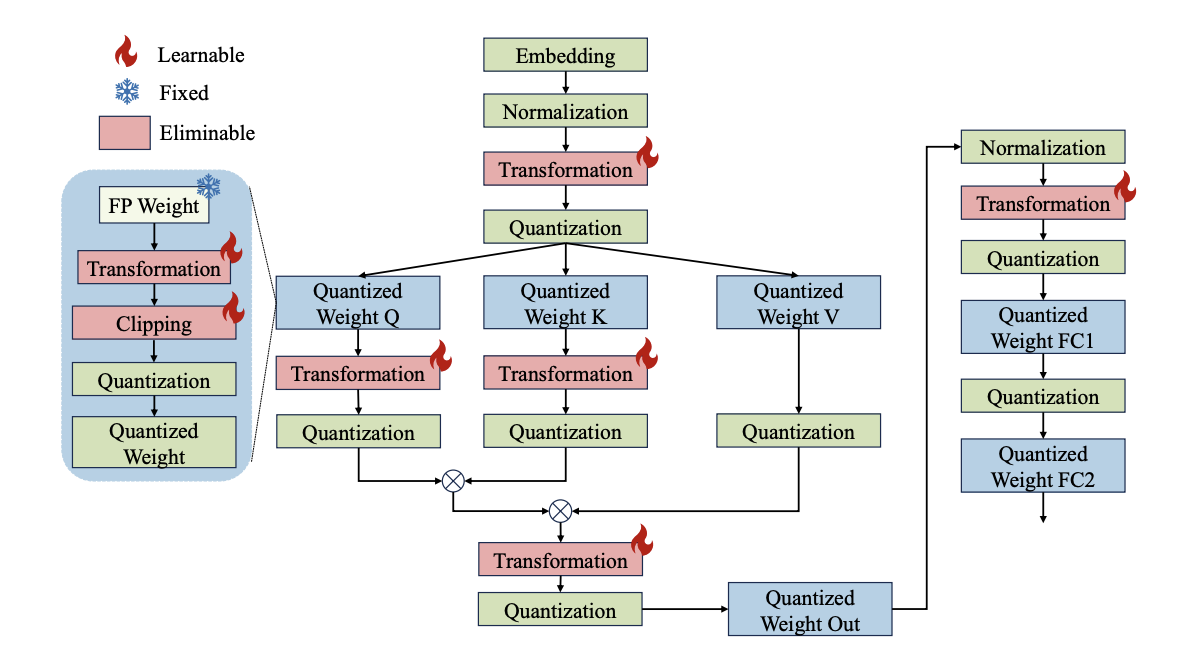
Learnable Weight Clipping
Optimal dynamic clipping threshold for weight distribution
Learnable Equivalent Transformation
Channel-wise scaling and shifting for activation distribution -> outlier issue
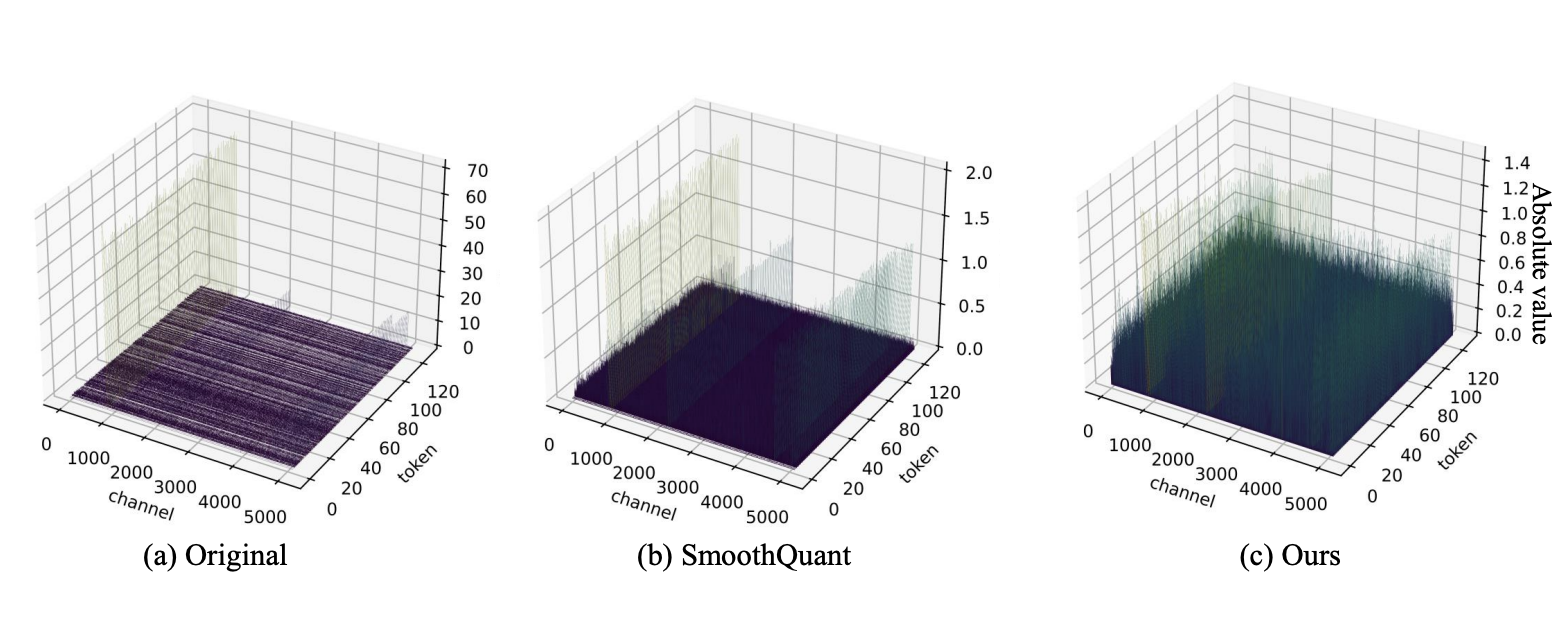
- SmoothQuant refer to Xiao, Guangxuan, et al. “Smoothquant: Accurate and efficient post-training quantization for large language models.” International Conference on Machine Learning. PMLR, 2023.
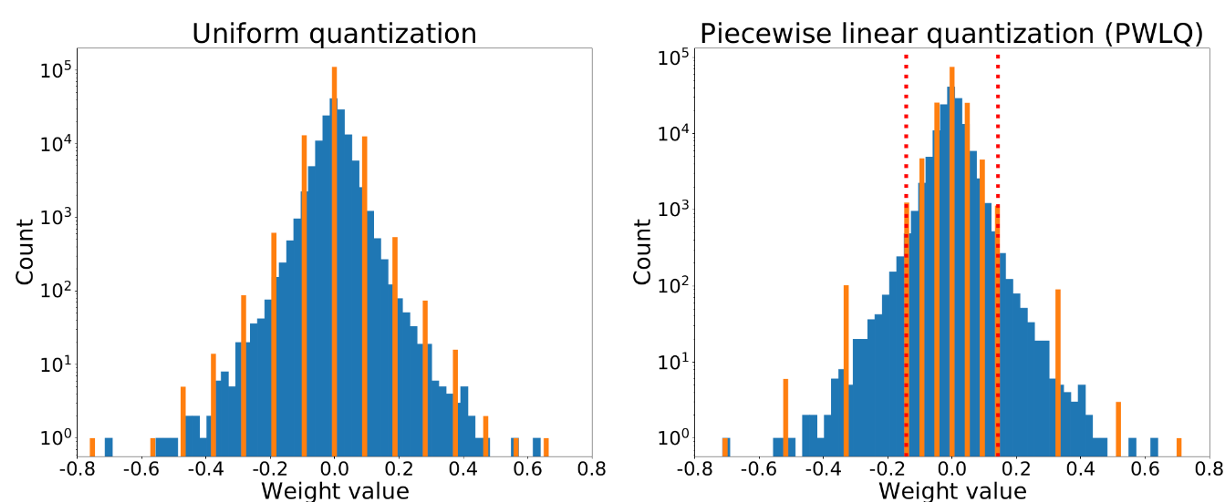
Piecewise Weight Quantization
Whether you’re building a website for your business, personal brand, or creative project, Frost is the perfect solution for anyone looking to launch a website quickly and efficiently.
.
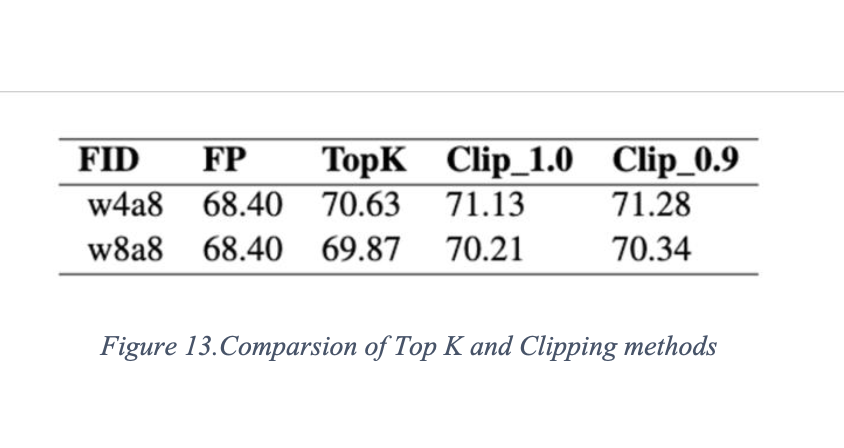
Activations Clipping
•Top10 —- The top-K method limits the range of activation values by keeping only the K largest (or smallest) values and discarding the rest.
•Clipping range —- The clip method limits the range of activation values by multiplying them with a clipping coefficient.