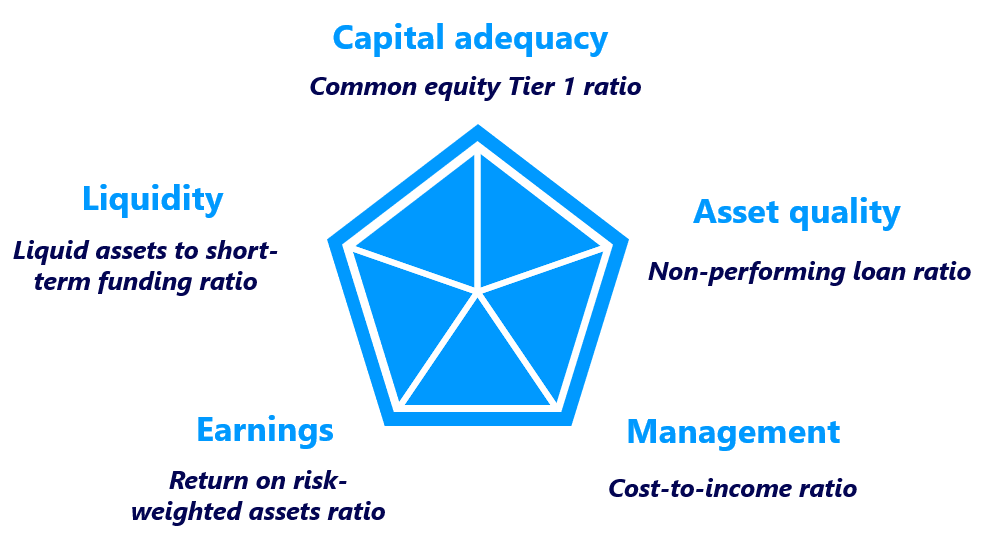
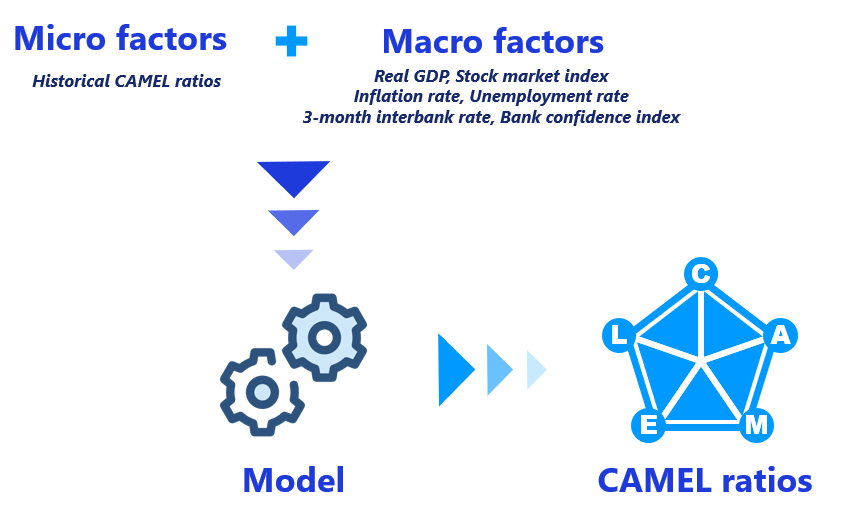
A forward-looking assessment of the risk profile of financial institutions is crucial in the CAMEL rating framework. To simulate such a profile quantitatively, this project will predict five financial ratios (CAMEL ratios).
The forecasting process involves the use of micro factors and macro factors as the inputs for the developed models to produce forecasts on the CAMEL ratios :
Data collection
Numerical data comprise financial and macroeconomic data. Financial data is obtained from Moody’s Analytics Orbis Bank Focus, and macroeconomic data is mainly sourced from CEIC Data. Data are collected from four other jurisdictions which have comparable supervisory framework for risk assessments in a broader scope (particularly in RVI assessment, i.e., peer group analysis).
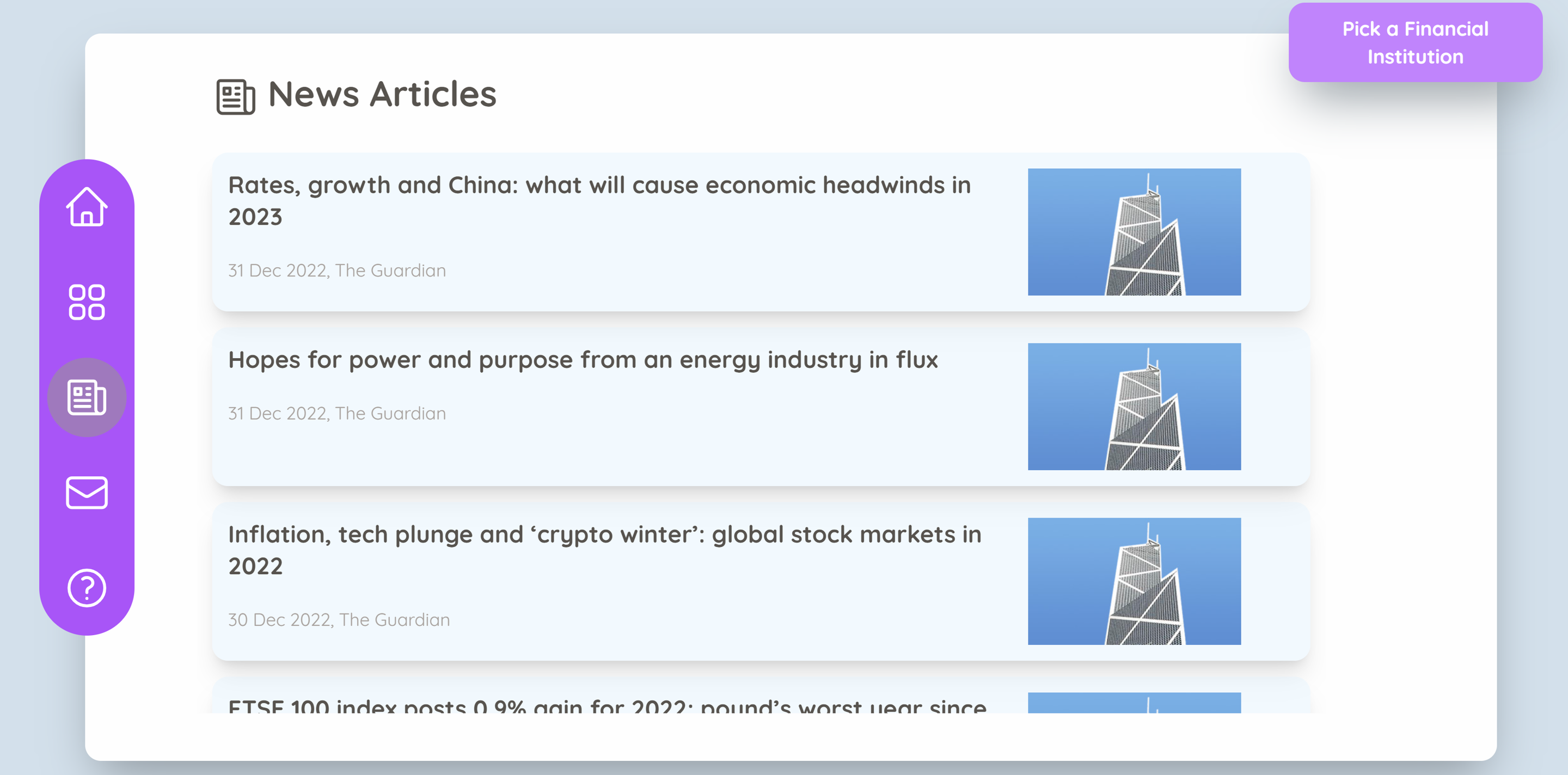
News articles were the main source of textual data. News from financial institutions in the Financial Stability Board‘s G-SIFI list were retrieved from The Guardian’s Open Platform.
Data processing
Numerical data are processed under standard data cleansing procedures. Moreover, bank selection is performed with similarity search to ensure non-local ratio data do not deviate much from the local data in each period.
News articles are processed using dictionary-based sentiment analysis. A Bank Confidence Index (BCI) for each period is constructed by computing the arithmetic mean of the sentiments of articles published within the period.
Model implementation
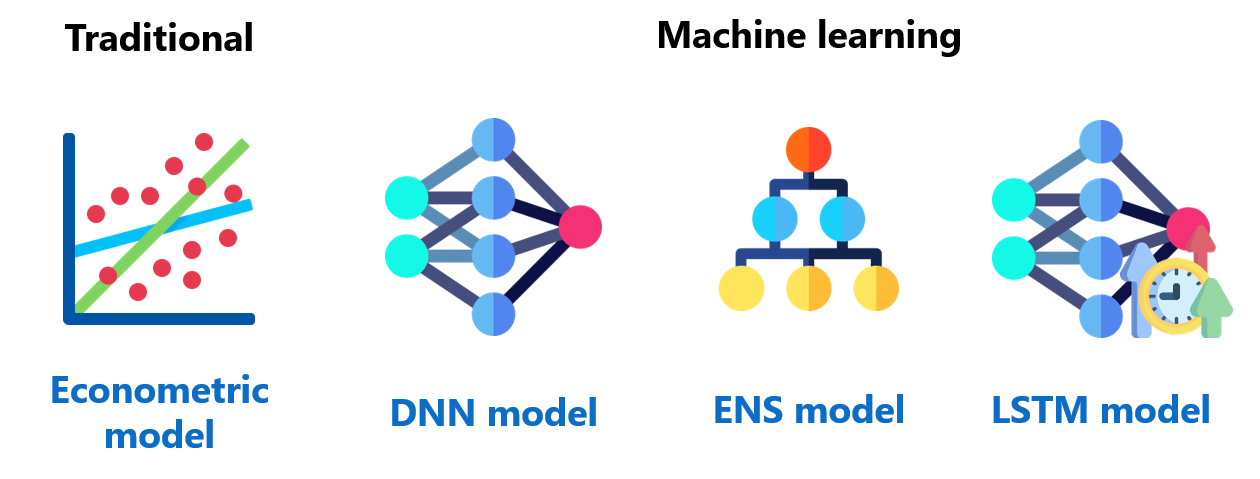
Models for implementing the CAMEL-based risk profile prediction include the traditional econometric model and machine learning model . Notably, the traditional econometric model is used as a benchmark for examining the forecasting performance of the machine learning model which is deemed to provide better accuracy in the context of risk profile prediction.
The economic model used in this project is a dynamic panel data model with fixed effects (linear regression); whereas, the machine learning models developed include a dense neural network (DNN) model, an ensemble (ENS) model , and a long short-term memory (LSTM) model.
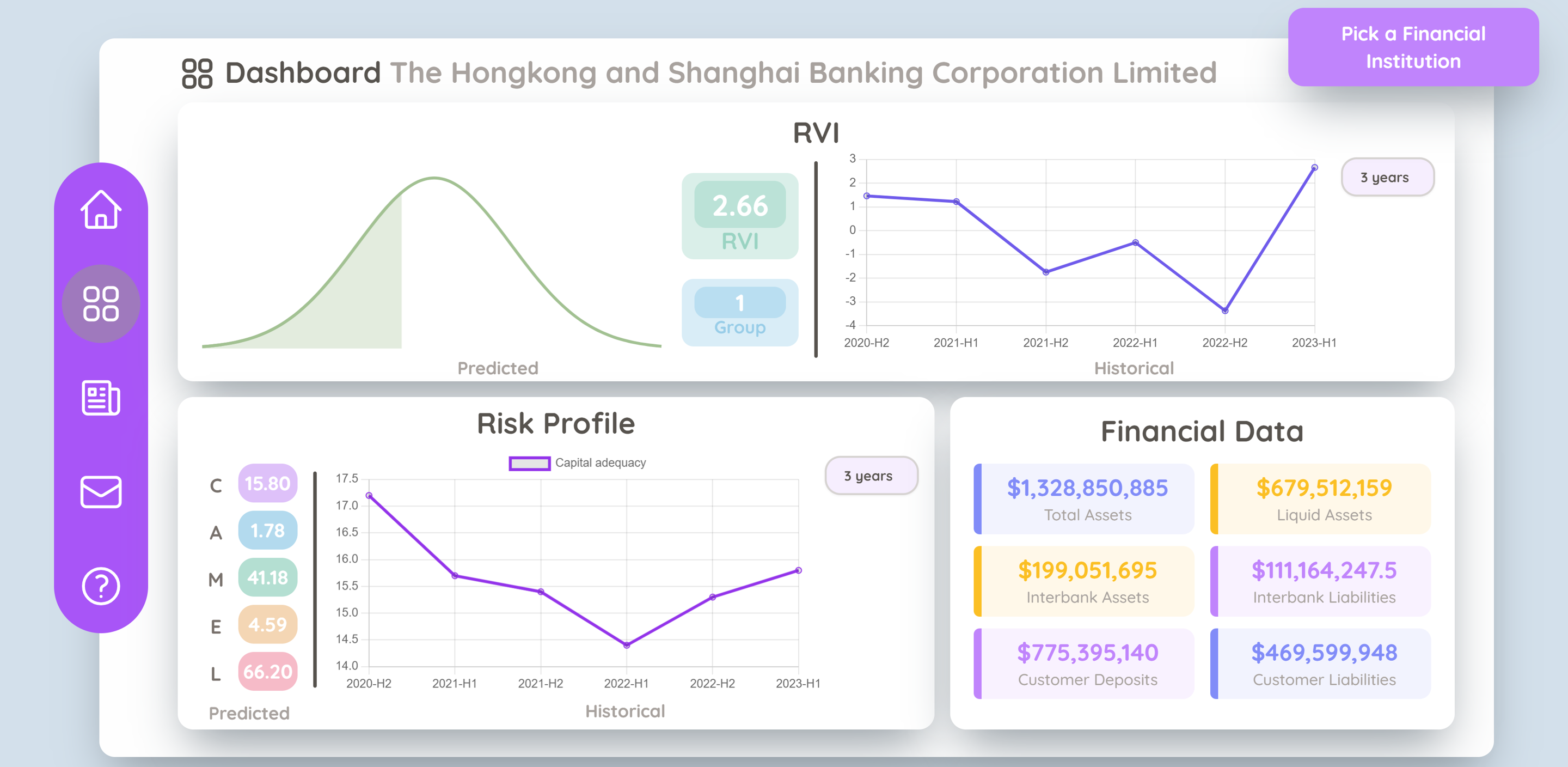
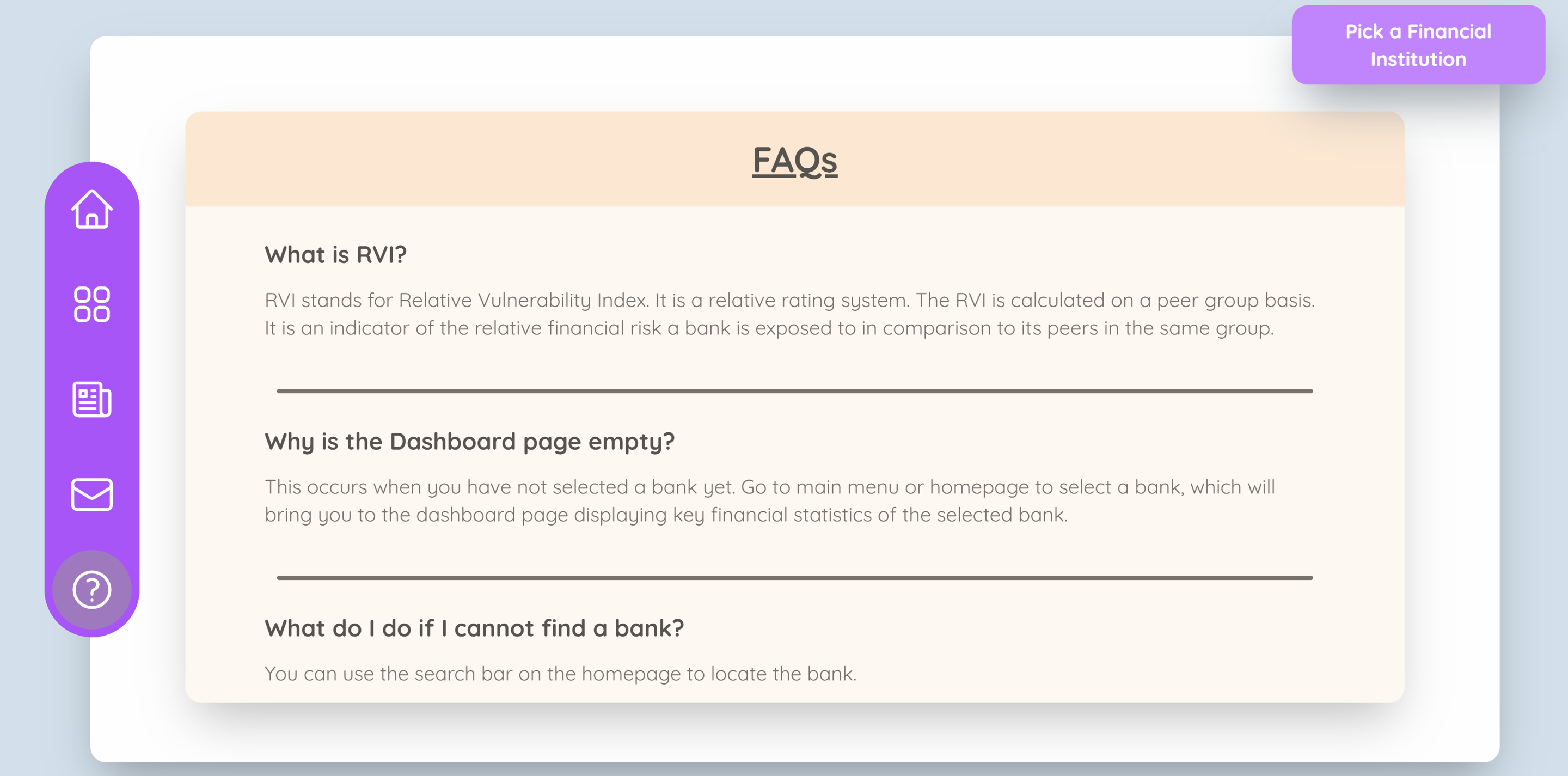
Relative vulnerability index (RVI)
To facilitate the current rating process, a Relative Vulnerability Index (RVI) is constructed to provide automatic evaluation of financial institutions’ vulnerabilities on a peer-group basis. This can be done by firstly creating different peer groups based on the level of systemic importance using K-means clustering, and then computing the Z-score of each representative ratio where its distribution is normalized using a machine learning technique, i.e, quantile transformation.
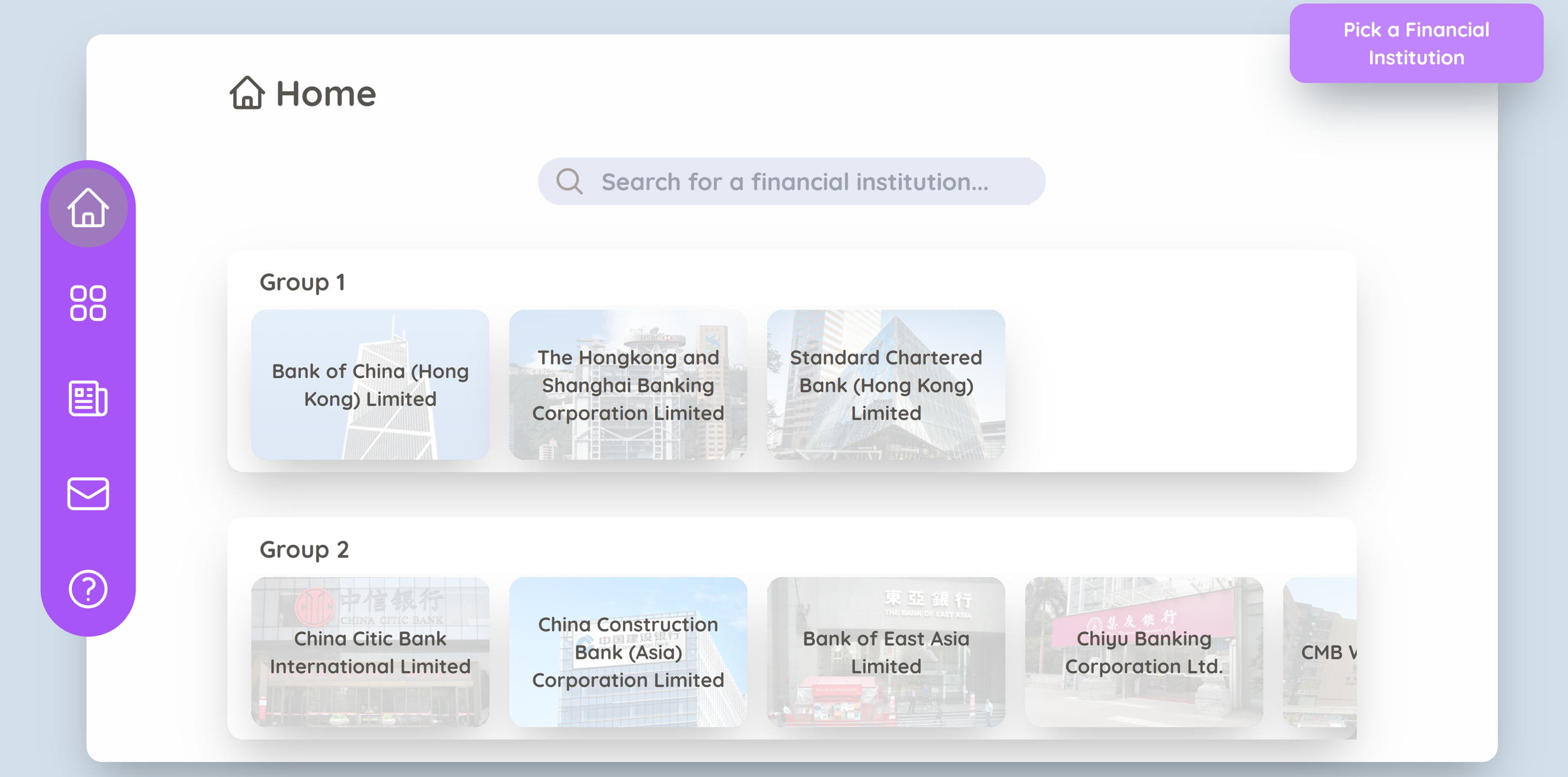
Web-Based Dashboard
The final product consists of 5 main pages:
Homepage: shows all financial institutions in each peer group
Dashboard Page: displays predicted and historical data on risk profile and RVI, and other key financial data
News Center: headlines of relevant news articles from the Guardian
Notifications Center: receive notifications on updates to the risk profile or RVI prediction results, and the latest news
FAQs Page: addresses common queries and explains terminology