Automatic Bass Transcription
Introduction
Welcome! This project attempts to design a proof-of-concept model that converts bass guitar audio into Western notation. The task is analogous to Automatic Speech Recognition, but with music and sheet notation (in Lilypond) instead of speech and natural language.
Motivation
Very little research has been conducted on notation-level transcription. From empirical results, most existing models do not perform well for bass. The primary goal is to establish such a model with a broader vision to serve as a useful tool for bassists and other musicians. After all, the world needs more bass players!
The Data
For this project, no suitable existing datasets were available. Therefore, the task includes generating bass guitar audio with corresponding labels in Lilypond format (inspired by this paper) to train the model. Data scarcity is a major problem for automatic music transcription; annotating music scores is an incredibly time-consuming and difficult task, even for musicians.
Lilypond
Part of the GNU project, Lilypond is a powerful music engraving toolset. It provides a nice and concise syntax for writing music notation and is widely adopted.

Data generation pipeline
- A Python script generates labels and Lilypond scores.
- The Lilypond CLI renders scores into MIDI
- The Reaper digital audio workstation renders generated MIDI with a virtual instrument (Ample Bass P Lite II) into audio files. Its scripting capabilities, along with the Ultraschall library, allows for automated rendering using a Lua script.

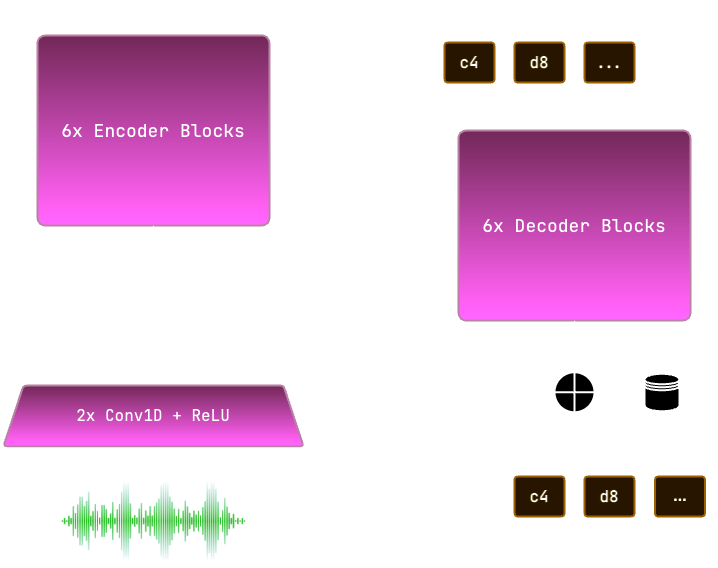
The Model
The model consists of a Convolutional Neural Network audio encoder and a Transformer implemented in PyTorch and trained from scratch. References and inspirations are from this paper and OpenAI Whisper.
Preliminary Results
The model achieved an average word error rate (WER) and character error rate (CER) of < 10%.