Data will first be pipelined from RapidAPI, the largest API platform in the world which allows integration of APIs into different applications. It will reduce the time and effort needed compared to individual searches for data sources. Additionally, the platform provides code snippets in JavaScript with detailed documentation to facilitate the integration process.
Shortlisted APIs include “FootApi” and “LiveScore Football” since they offer real-time football data like league table standings, fixtures, match detail, etc., with latency as low as 159 milliseconds and a rate limit of 5 requests per second, which is sufficient for the project scope.
After obtaining data from the aforementioned APIs, cleaning will then be performed to remove redundant attributes and maintain consistency. For example, players’ full names and playing positions will be unified. Moreover, additional columns like the shortened club and player names may be created in the database for frontend display.
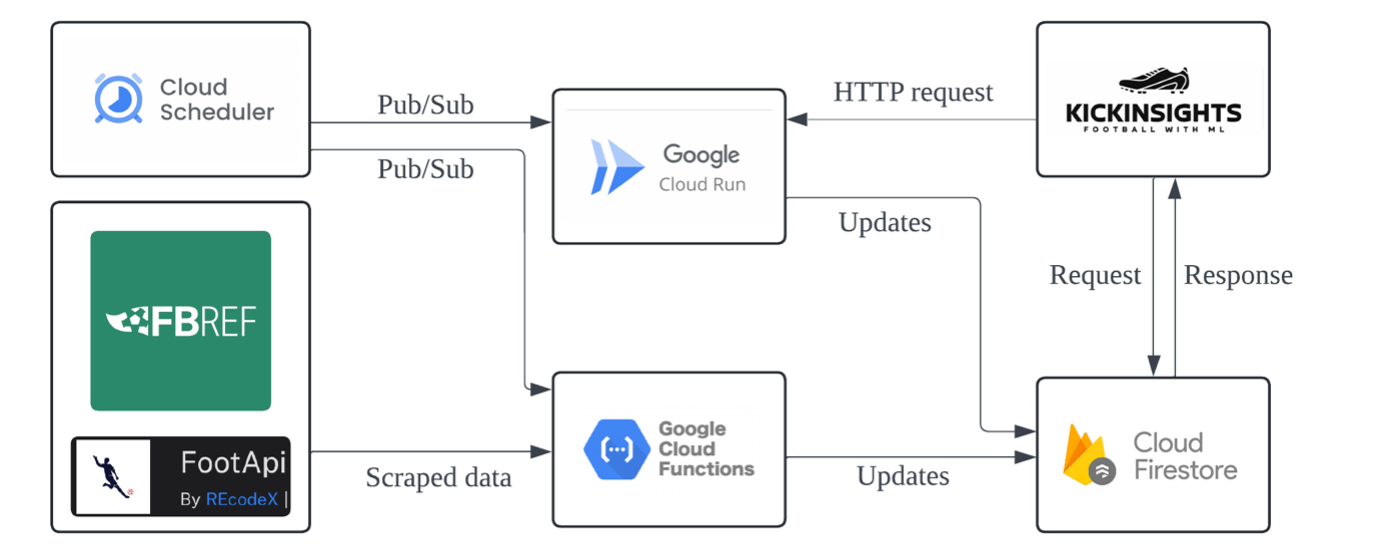
A total of 23 scripts for data wrangling are run on Google Cloud Functions, in which 21 are written in JavaScript, and the remaining 2 for the ML prediction system are written in Python. Data wrangling functions are triggered by Pub/Sub topics generated from the Google Cloud Scheduler to ensure that the latest data are updated inside the Firestore database. Each function is allocated with 256 MB of virtual memory. The two Python scripts for ML are deployed with Google Cloud Run, as it supports a maximum timeout duration of 60 minutes against the 9 minutes by Cloud Functions. So, the ML wrangling and training functions are provided with a 2nd Gen environment with 6 vCPUs, and allocated with 1 and 4 GiB of memory respectively. This supports high-speed model training after it receives HTTP requests from the KickInsights app for training models.
Each cloud function has its own schedule for being updated , depending on the premier league’s match date and time, FBREF and FootApi’s fetch limit, and Firestore’s usage quota, etc. to minimize fetching costs. For example, most matches are played on weekends so the running frequency is higher on Saturdays and Sundays. Also, the schedule adapts to FBREF’s updated time between 6-8 am (UTC +8).
Machine Learning Prediction System
As shown in the previous section, data wrangling and model training are separated into two functions. This allows a much shorter time required for training the model when users are waiting for the evaluation results. The data wrangling function is triggered by the Cloud Scheduler periodically to update the Firestore database. It first scrapes data of matches from FBREF, filters and transforms the useful data, and then computes the aggregate values and rolling averages of all attributes of each match. This ensures that every time a model is trained, all data are readily available in the database.
When a user submits a training request in the KickInsights app, an HTTP request is sent to trigger the ML training function. The app only needs to collect the user input, like checkboxes ticked and dropdowns selected, and then transfer the request without any actual training data. This minimizes the traffic flow between the app and the backend program. Upon receiving the user inputs, the model training function first selects the required data columns and rows from the Firestore database, then pipeline the matches’ data into the involved algorithms, powered by Scikit-learn. It then compares the predicted match outcome against the actual outcome in the testing dataset to calculate the accuracy, precision, and F1 score under different confidence levels. Lastly, the confusion matrices, model performance graph, and feature importance chart are generated and sent back to the KickInsights app together with the predicted results.
Backend Infrastructure
The application backend and database will be constructed with Firebase, Google’s BaaS which provides robust infrastructure for data storage. The distributed architecture not only provides load balancing for app usage but also syncs data in real time across data centres, preventing bottlenecks at any specific server.
The wrangled football data will be stored in the Google Cloud Firestore while club logos and player pictures will be stored in the Firebase Storage, as they support offline access of app resources since the previous update. They also offer great scalability and data handling capabilities under a cost-effective pricing scheme based on actual usage.
Google’s Cloud Run API will be used to serve app requests to build, train, and evaluate the ML models because it is fully compatible with the Node.js framework and Firestore, allowing developers to deploy code using a simple command-line interface. For developing the ML components, Python libraries like pandas, numpy, and scikit-learn are used as they cater to diverse models from traditional SVMs and clusterings to advanced artificial neural networks.